

The Return
Eight years between builds. Not because I stopped caring about hardware, but because life repositioned me. Post-2019, work pulled me into the Mac ecosystem - my days at AgriSync, then the Deere transition. By 2022, I did relocate to the US, and the rhythm shifted hard enough that hobbyist machine-building went dormant.
But it never disappeared. It just waited.
TISYA - Sanskrit for "auspicious," named in the tradition - built March 31, 2025, closes the trilogy. Triga (2014) taught me what mattered in hardware tradeoffs. Thanos (2017) was the refinement. Tisya is the return: same ritual, evolved motivations.
Why Now
Three things converged.
Weekend SaaS building. I am back in builder mode - writing code, running services locally, iterating fast on a platform for communications. Weekend hack projects are back. Docker containers, local databases, API prototyping - I needed a machine that could handle whatever I threw at it without waiting on cloud instances or fighting with tooling on a Mac.
AI/ML workloads. My spouse is finishing a Degree in Computer Science - AI/ML, graduates May 2026. She was deep into her semesters when we built Tisya for GPU-heavy assignments, model training, PyTorch experimentation. Local compute was very helpful.
The joy of building. I have always built machines for learning, not gaming. Every few years I might install an old classic, play for 2-3 hours, then move on. But the process - researching parts, making tradeoff decisions, assembling it myself, watching it POST for the first time - that's what I missed. Building machines is one of the few hobbies where I get to spend money on something tangible, learn constantly, and end up with a tool I actually use.
The Build - Specs
| Component | Part |
|---|---|
| Motherboard | ASUS ProArt X870E-CREATOR WiFi (AM5, X870E chipset) |
| CPU | AMD Ryzen 9 9950X3D (16-core, Zen 5 with 3D V-Cache) |
| GPU | NVIDIA GeForce RTX 5080 Founders Edition (16GB GDDR7) |
| GPU (bridge) | NVIDIA GeForce RTX 3090 Founders Edition (24GB) — sold after ecosystem matured |
| RAM | Corsair Vengeance DDR5 96GB (2x48GB) 6000MHz CL30 |
| Storage | Samsung 990 PRO 4TB NVMe Gen4 (PCIe 4.0 x4) |
| PSU | Corsair RM1000x Shift (1000W, ATX 3.1, PCIe 5.1, 80 Plus Gold) |
| Cooling | Corsair Nautilus 360 RS AIO (360mm radiator, RS120 fans) |
| Case | Corsair 4000D Airflow (mid-tower, high airflow mesh front) |
| OS | Windows 11 |
Platform Choice: AM5 and Future-Proofing
AM5 was the obvious call. AMD's current platform with a long upgrade path, DDR5 support, PCIe 5.0 lanes for future GPU headroom. The 9950X3D gave me 16 Zen 5 cores with 3D V-Cache - massive L3 cache for compute-heavy workloads (compilation, AI training, parallel builds). 96GB of DDR5-6000 meant no memory bottlenecks on large datasets, multi-container dev environments, or simultaneous model training runs.
The ProArt X870E-CREATOR deserves its own callout: Dual PCIe 5.0 x16 slots, Thunderbolt 4, 10GbE + 2.5GbE networking, WiFi 7, four M.2 slots. Built for creator workflows, which maps cleanly to AI/ML experimentation and software development. No RGB nonsense. Just expansion, bandwidth, and rock-solid BIOS stability.
Storage: Samsung's 990 PRO 4TB. Gen4 NVMe, 7,450 MB/s sequential read. Fast enough that loading large datasets, Docker image layers, and model checkpoints never feel like waiting.
The Hero Component: RTX 5080 and the Blackwell Bet
NVIDIA GeForce RTX 5080 Founders Edition (16GB GDDR7)
This was the centerpiece decision - and the riskiest one.
NVIDIA's Blackwell architecture (50-series) launched in early 2025. The 5080 sits in a sweet spot: best-in-class for home users, 16GB of GDDR7 VRAM, massive AI inference and training performance gains over Ampere and Ada. But early adoption always carries risk. Driver stability, framework support (PyTorch, TensorFlow, CUDA toolkit), and tooling maturity all lag behind hardware launches.
We hit that friction immediately. During the first few days post-build, the Blackwell ecosystem wasn't ready - SDKs hadn't caught up, some AI libraries threw compatibility errors, GPU-accelerated workflows that should have "just worked" didn't. My spouse needed the machine now for coursework, so I bought an RTX 3090 Founders Edition (24GB) as a pragmatic fallback. It gave us a second GPU with mature ecosystem support while Blackwell stabilized.
The bet paid off. Within weeks, PyTorch released Blackwell-optimized binaries, CUDA 12.6+ closed the compatibility gaps, and Ollama added native 50-series support. The 5080 became the primary GPU, and the 3090 moved to the marketplace. We're 5080-only now.
Would I get a 5090 someday? Maybe. But the 5080 does everything we need right now, and the next upgrade will probably be the 60-series or whatever NVIDIA ships in 2027-2028. The 3090-bridge strategy let us stay unblocked during ecosystem immaturity without betting the entire build on vaporware driver promises.
Assembly: March 31, 2025
I haven't built a machine since 2017, so relearning the rhythm took a minute. Cable management is easier now - the 4000D Airflow has excellent PSU shroud clearance and rear cable routing channels. Modern GPUs are massive - the 5080 Founders Edition is a 3+ slot card with significant weight. I used a GPU support bracket to avoid motherboard sag.
The Nautilus 360 RS AIO mounts cleanly on AM5 (updated bracket included). 360mm radiator on front exhaust, three RS120 fans pulling air through. The 9950X3D stays cool even under sustained multi-core load - video encoding, parallel compilation, AI training. Temps never break 70°C.
POST was clean on the first boot. BIOS detected everything. RAM ran at XMP 6000MHz without fuss. Windows 11 installed in under 15 minutes. The satisfaction of watching a machine you built yourself come to life - that never gets old.
Triga → Thanos → Tisya
Three machines. Three eras.
Triga (2014): The first formal hobbyist build. I was learning what mattered in hardware, what tradeoffs to make, how to balance performance and budget.
Thanos (2017): The refinement. I knew what I wanted by then, and I built accordingly.
Tisya (2025): The return. Eight years later, with different motivations but the same ritual. I build machines when I need them and when I am ready to make something again.
The hobby never left. It just went quiet for a while.
The Numbers
PassMark Performance Testing - April 6, 2025
Tisya scored in the 99th percentile across every major benchmark category. Here's how it stacks up against global averages:
Overall PassMark Rating: 18,317 (99th percentile, 3.25x world average)
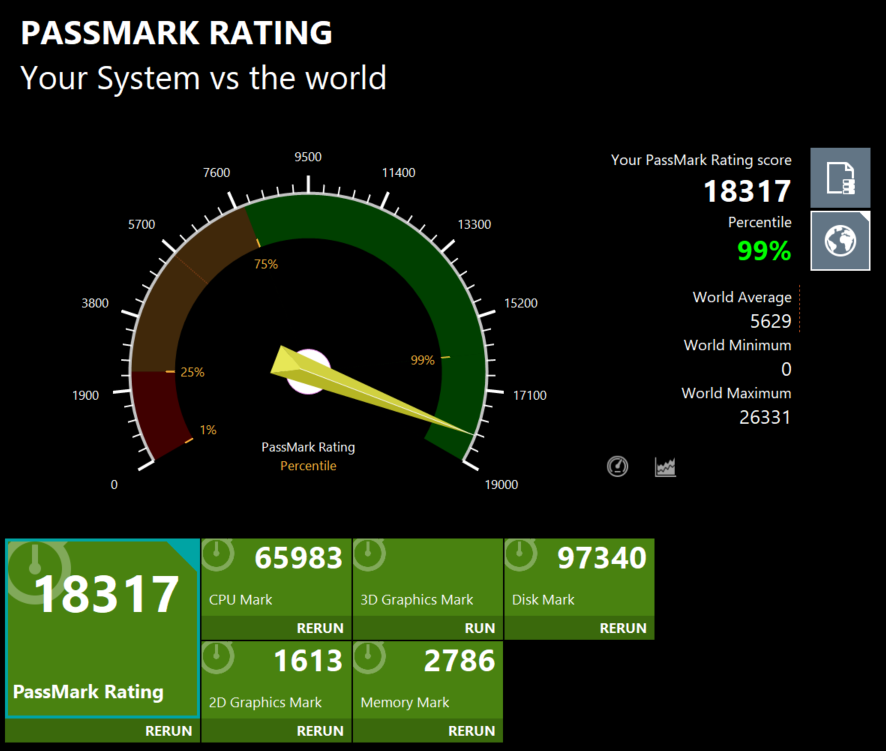
CPU Mark: 65,983 (99th percentile, 3.5x world average)
- Integer Math: 234,952
- Floating Point: 158,618
- Compression: 936,020
- Physics: 3,167
- Extended Instructions (SSE): 67,443
- Encryption: 44,351
- Sorting: 85,175
- Single-Threaded: 4,700
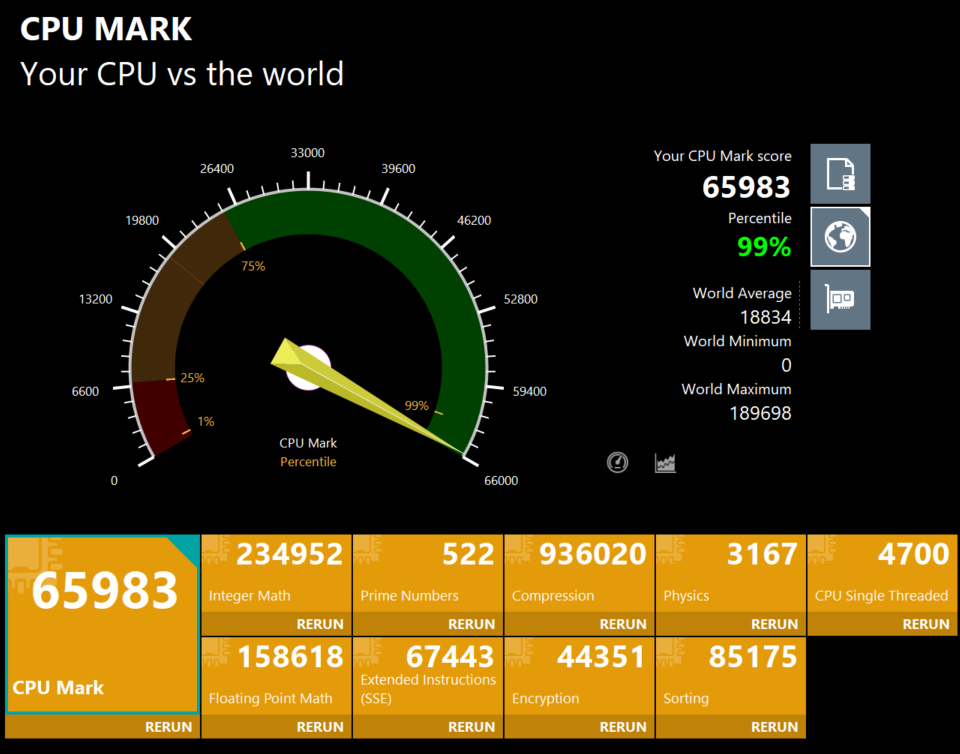
GPU Compute Mark: 22,023 (99th percentile, 3.6x world average)
The 5080 dominates GPU compute workloads — DirectX 9/10/11/12 rendering, parallel operations per second. This translates directly to faster AI model inference, training acceleration, and CUDA-based scientific computing.
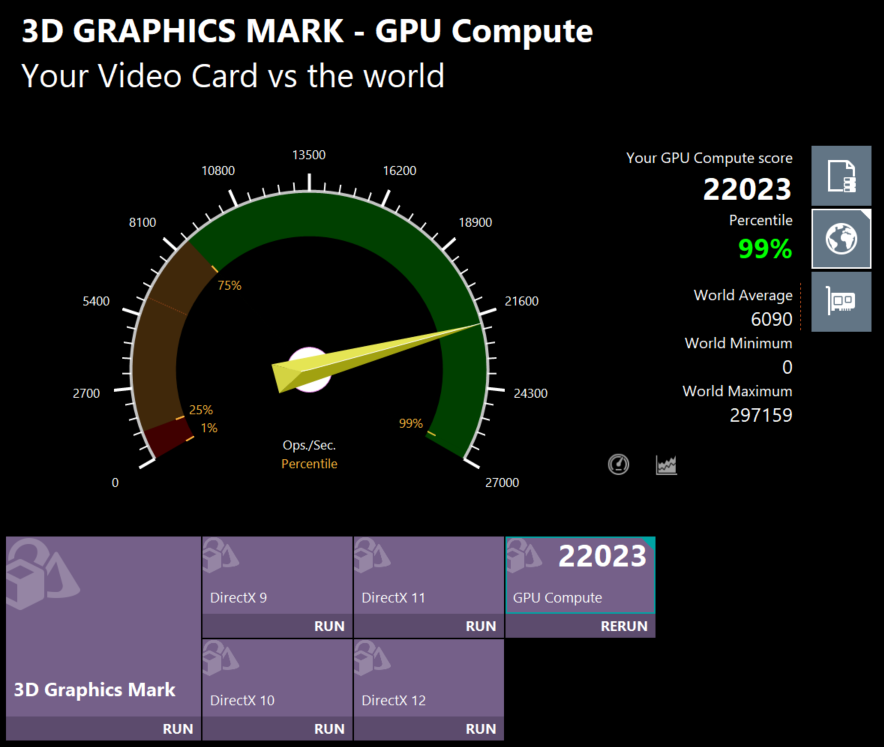
2D Graphics Mark: 1,613 (99th percentile, 2.4x world average)
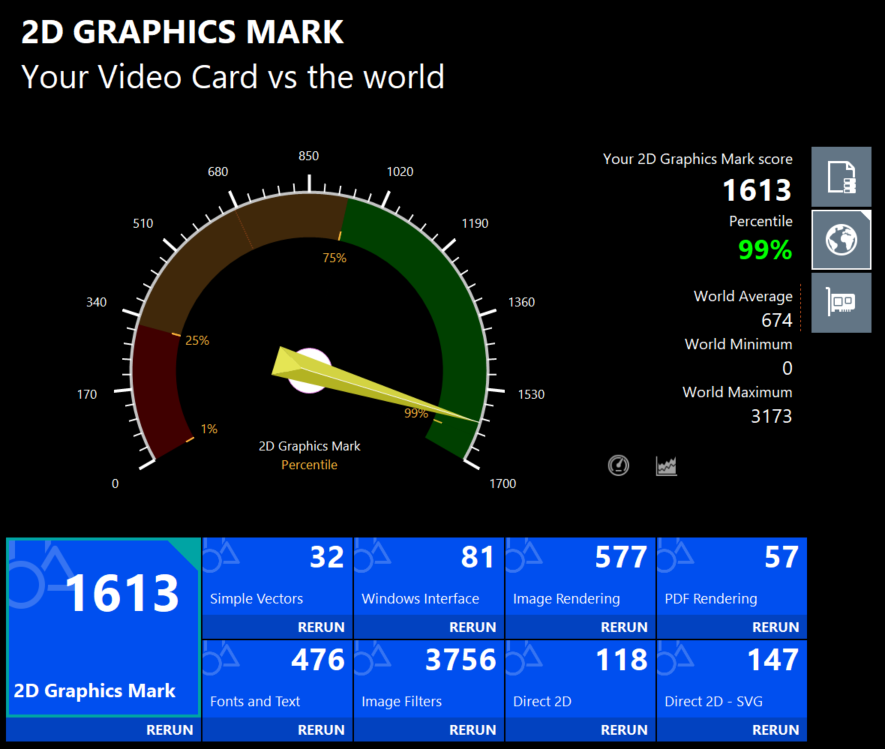
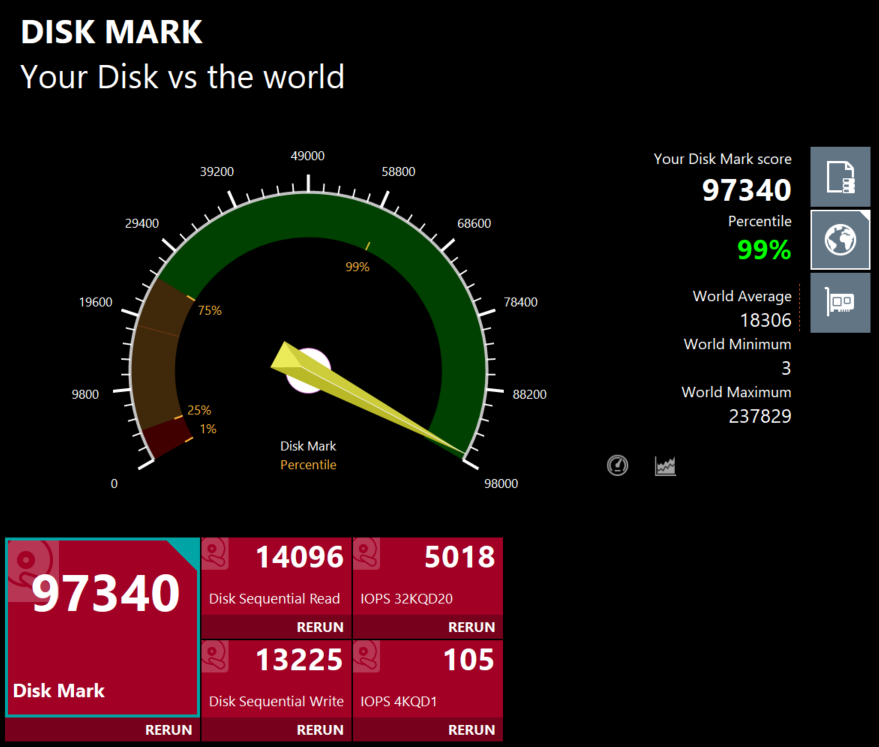
Disk Mark: 97,340 (99th percentile, 5.3x world average)
- Sequential Read: 14,096 MB/s
- Sequential Write: 13,225 MB/s
Samsung's 990 PRO 4TB hitting advertised speeds. Loading large datasets, Docker layers, and model checkpoints is effectively instantaneous.
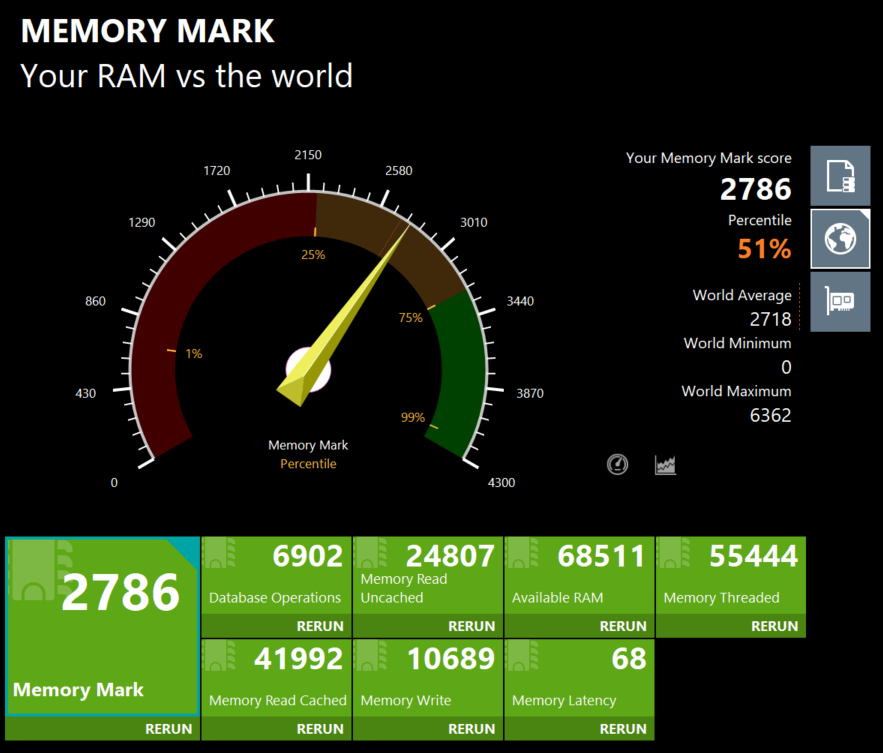
Memory Mark: 2,786 (51st percentile)
- Database Operations: 6,902
- Memory Read (Uncached): 24,807 MB/s
- Available RAM: 68,511 MB
- Memory Threaded: 55,444
- Memory Read (Cached): 41,992 MB/s
- Memory Write: 10,689 MB/s
- Latency: 68 ns
DDR5-6000 performs exactly as expected. The 51st percentile ranking is misleading - it is not a bottleneck, just a reflection of how fast high-end DDR5 has become across the market. 96GB capacity matters more than raw bandwidth for AI workloads anyway.
AI Training Performance: RTX 5080 vs RTX 3090
Workload: ResNet-50 training on CIFAR-10 dataset (20 epochs, PyTorch 2.8.0, CUDA 12.8)
Test date: April 5, 2025
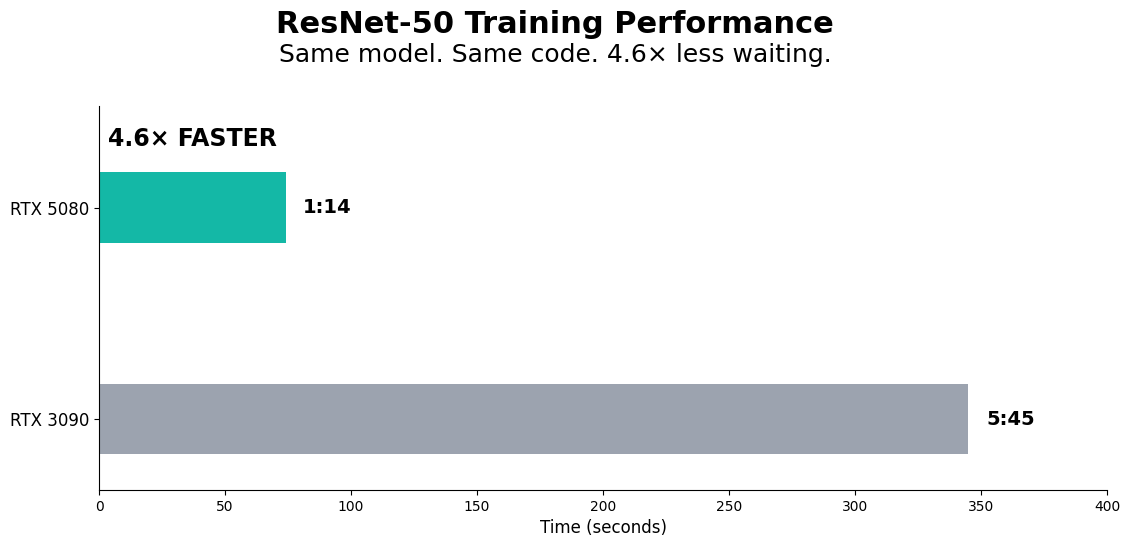
| Metric | RTX 3090 | RTX 5080 | Speedup |
|---|---|---|---|
| Avg. Epoch Time | 5:45 | 1:14 | 4.6x faster |
| Final Accuracy | 80.90% | 82.74% | +1.84pp |
| Total Training Time | 1h 55m | 25m | 4.6x faster |
The 5080 isn't just faster - it converges better. Same workload, better final accuracy, in a fraction of the time. That's Blackwell's architectural win: tensor core improvements, memory bandwidth gains, and actual compute efficiency that matters when you're iterating on models locally.
For context: cutting epoch time from ~6 minutes to ~1 minute means the difference between running 3 experiments per hour vs. 1 experiment every 2 hours. When you're tuning hyperparameters or testing architectural changes, that iteration speed compounds fast.

Triga (2014)
Thanos (2017)